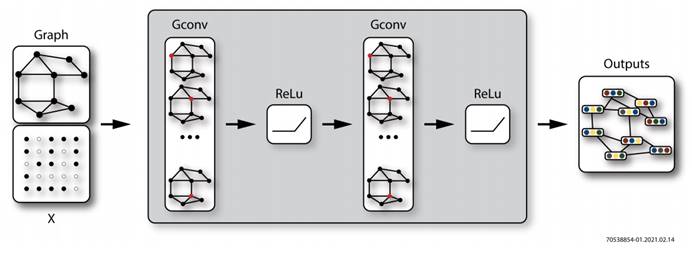
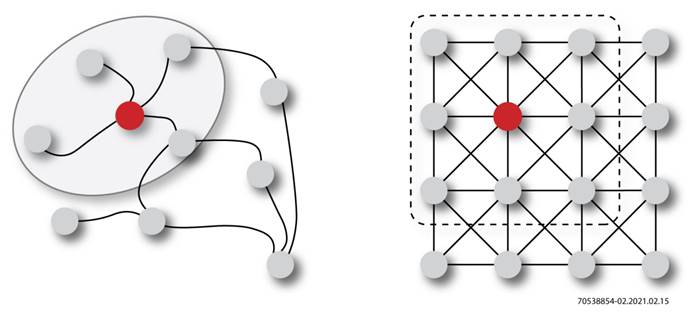
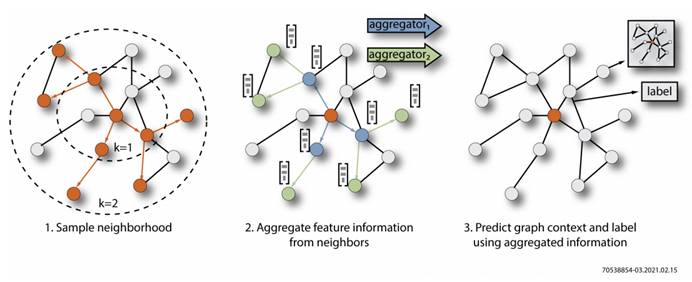
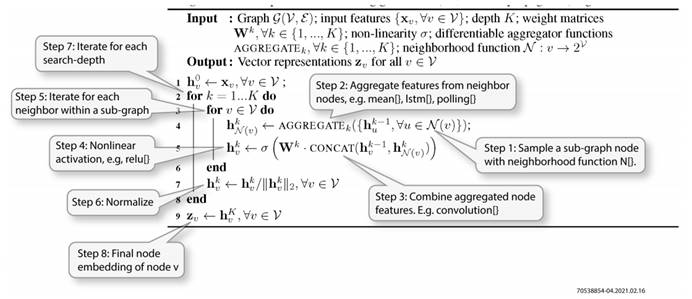

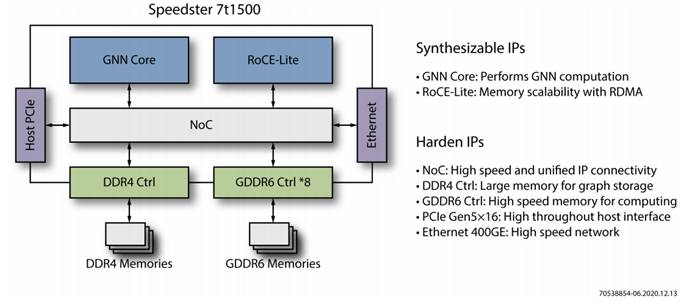
| GNN设计所面临的挑战 | Speedster AC7t1500器件提供的解决方案 |
| 高速矩阵运算 | 机器学习处理器(MLP) |
| 高带宽和低延迟存储 | LRAM+BRAM+Gddr6+ddr4。 |
| 高并发和低延迟计算 | FPGA使用可编程逻辑电路,以确保在硬件层面进行低并发和高并发延迟计算。 |
| 存储扩展 | 基于4×400 Gbps的RDMA确保在数据中心以极低的延迟扩展存储访问。 |
| 算法不断演进 | FPGA中的可编程逻辑确保算法可以在硬件层面进行升级和重新配置。 |
| 复杂的设计 | 丰富的硬IP减少开发时间、降低复杂性,NoC简化模块之间的互连并改善时序 |
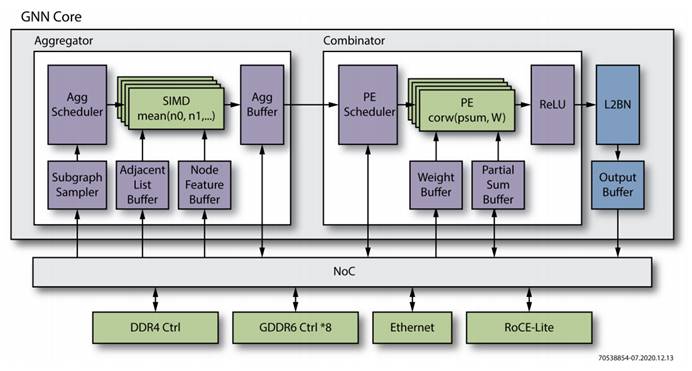
| 步骤 | 聚合操作 | 合并操作 |
| 存储访问方式 | 间接访问,不规则 | 直接访问,规则 |
| 数据重用 | 低 | 高 |
| 计算模式 | 动态,不规则 | 静态,规则 |
| 计算量 | 低 | 高 |
| 性能瓶颈 | 存储 | 计算 |
| 欢迎光临 EDA365电子论坛网 (https://bbs.eda365.com/) | Powered by Discuz! X3.2 |