EDA365电子论坛网
标题: 创龙带您解密TI、Xilinx异构多核SoC处理器核间通讯 [打印本页]
作者: Tronlong小分队 时间: 2020-3-26 09:41
标题: 创龙带您解密TI、Xilinx异构多核SoC处理器核间通讯
一、什么是异构多核SoC处理器
顾名思义,单颗芯片内集成多个不同架构处理单元核心的SoC处理器,我们称之为异构多核SoC处理器,比如:
- TI的OMAP-L138(DSP C674x + ARM9)、AM5708(DSP C66x + ARM Cortex-A15)SoC处理器等;
- Xilinx的ZYNQ(ARM Cortex-A9 + Artix-7/Kintex-7可编程逻辑架构)SoC处理器等。1 |% k- X- P; U* w# e h; m
二、异构多核SoC处理器有什么优势
相对于单核处理器,异构多核SoC处理器能带来性能、成本、功耗、尺寸等更多的组合优势,不同架构间各司其职,各自发挥原本架构独特的优势。比如:
- ARM廉价、耗能低,擅长进行控制操作和多媒体显示;
- DSP天生为数字信号处理而生,擅长进行专用算法运算;
- FPGA擅长高速、多通道数据采集和信号传输。8 g# E0 b" u8 s3 H* x& ]$ E
同时,异构多核SoC处理器核间通过各种通信方式,快速进行数据的传输和共享,可完美实现1+1>2的效果。
三、常见核间通信方式
要充分发挥异构多核SoC处理器的性能,除开半导体厂家对芯片的硬件封装外,关键点还在于核间通信的软硬件机制设计,下面介绍几种在TI、Xilinx异构多核SoC处理器上常见的核间通信方式。
- OpenCL0 q6 k' c) O! a7 ^& S" }
OpenCL(全称Open Computing Language,开放运算语言)是第一个面向异构系统通用目的并行编程的开放式、免费标准,也是一个统一的编程环境,便于软件开发人员编写高效轻便的代码,而且广泛适用于多核心处理器(CPU)、图形处理器(GPU)、Cell类型架构以及数字信号处理器(DSP)等其他并行处理器,在能源电力、轨道交通、工业自动化、医疗、通信、军工等应用领域都有广阔的发展前景。
& Q. c' ~0 M8 {& H% L5 x* Q在异构多核SoC处理器上,OpenCL将其中一个可编程内核视为主机,将其他内核视为设备。在主机上运行的应用程序(即主机程序)管理设备上的代码(内核)的执行,并且还负责使数据可用于设备。设备由一个或多个计算单元组成。比如,在TI AM5728异构多核SoC处理器中,每个C66x DSP都是一个计算单元。! {+ ]4 c- J$ {- `( |

% F: @: D. H* Z7 @; l7 n3 t7 oOpenCL运行时,一般包含如下两个组件:
9 ^0 H- y0 _/ o, Z$ _# G- 主机程序创建和提交内核以供执行的API。
- 用于表达内核的跨平台语言。7 B2 i9 y8 E: n3 ]
2.DCE
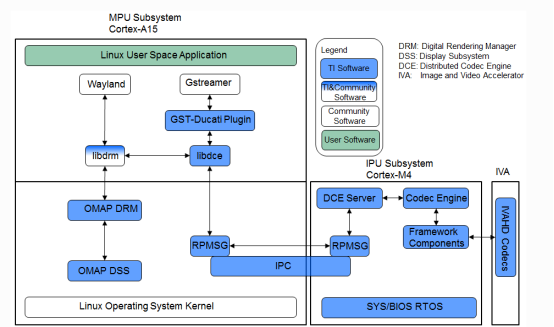
DCE(Distributed Codec Engine)分布式编解码器引擎,是TI基于AM57x异构多核SoC处理器的视频处理框架,提供的完整Gstreamer插件框架。
0 M$ Z N9 w0 {- u8 ?/ |. f- WDCE由三部分硬件模块组成,分别为MPU核心、IPU2核心以及IVA-HD硬件加速器,其主要功能如下:
; F1 X; r$ ^% ?6 U2 Q" g, ~5 A5 ~MPU:基于ARM用户空间Gstreamer应用,控制libdce模块。libdce模块在ARM RPMSG框架上实现与IPU2的IPC通信。
) c. B# m; j& H3 A8 W0 R; F- M4 V: B# VIPU2:构建DCE server,基于RPMSG框架与ARM实现通信,使用编解码器引擎和帧组件控制IVA-HD加速器。# S# W$ l( F ]0 X# h& F
IVA-HD:实现视频/图像编解码的硬件加速器。
3.IPC
IPC(Inter-Processor Communication)是一组旨在促进进程间通信的模块。通信包括消息传递、流和链接列表。这些模块提供的服务和功能可用于异构多核SoC处理器中ARM和DSP核心之间的通信。
- L* [1 l0 f' e, e3 }2 d6 t' e! a' v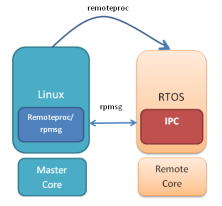 3 T) `) `6 o8 v( _6 Z; o
3 T) `) `6 o8 v( _6 Z; o
如下为TI异构多核SoC处理器常用的核间通信方式的优缺点比较:
% c8 s, G+ g* y K5 Q2 f
方式 | 优点 | 缺点 |
| - 易于在设备之间移植
- 无需了解内存架构
- 无需担心MPAX和MMU
- 无需担心一致性
- 无需在ARM和DSP之间构建/配置/使用IPC
- 无需成为DSP代码、架构或优化方面的专家; n! t# w# g, X# u
| - 无法控制系统内存布局等以处理优化的DSP代码
& F9 D+ K$ N( p7 t4 Z8 b2 f
|
| - 加速多媒体编解码处理
- 在与Gstreamer和TI Gstreamer插件连接时简化多媒体应用程序的开发
: b1 }3 W" h; b5 S/ d' |- D
| - 不适合非编解码算法
- 需要努力添加新的编解码算法
- 需要DSP编程知识6 l h! G0 o. d% v* m# X
|
| - 完全控制DSP配置
- 能够进行DSP代码优化
- 在多个TI平台上支持相同的API
* y8 g% f5 e2 f% h
| - 需要了解内存架构
- 需要了解DSP配置和编程
- 仅限于小型消息(小于512字节)
- TI专有API
/ |" A0 H! |! b& J# R
# `' C# p! s! b% Z
|
4.AXI
r0 G1 t& z7 c- D+ R6 W* P" GAXI(Advanced eXtensible Interface)是由ARM公司提出的一种总线协议,Xilinx从6系列的FPGA开始对AXI总线提供支持,目前使用AXI4版本。3 D4 s: D1 P1 V1 _
 $ f6 ~* v+ J, B& a6 A/ l
$ f6 ~* v+ J, B& a6 A/ l
ZYNQ有三种AXI总线:# c1 @2 `3 C2 r& k
(A)AXI4:(For high-performance memory-mapped requirements.)主要面向高性能地址映射通信的需求,是面向地址映射的接口,允许最大256轮的数据突发传输。- o0 M( ]9 G2 n$ \& v
(B)AXI4-Lite:(For simple, low-throughput memory-mapped communication.)是一个轻量级的地址映射单次传输接口,占用很少的逻辑单元。! T0 O# t; [' b0 @& W
(C)AXI4-Stream:(For high-speed streaming data.)面向高速流数据传输,去掉了地址项,允许无限制的数据突发传输规模。
AXI协议的制定是要建立在总线构成之上的。因此,AXI4、AXI4-Lite、AXI4-Stream都是AXI4协议。AXI总线协议的两端可以分为分为主(master)、从(slave)两端,他们之间一般需要通过一个AXI Interconnect相连接,作用是提供将一个或多个AXI主设备连接到一个或多个AXI从设备的一种交换机制。6 ?$ {& Q3 @. {! a9 I6 r
AXI Interconnect的主要作用是:当存在多个主机以及从机器时,AXIInterconnect负责将它们联系并管理起来。由于AXI支持乱序发送,乱序发送需要主机的ID信号支撑,而不同的主机发送的ID可能相同,而AXI Interconnect解决了这一问题,他会对不同主机的ID信号进行处理让ID变得唯一。3 d& H7 C) Y" @' v, C4 H
AXI协议将读地址通道、读数据通道、写地址通道、写数据通道、写响应通道分开,各自通道都有自己的握手协议。每个通道互不干扰却又彼此依赖。这是AXI高效的原因之一。: a3 i* }; x& l9 ~7 A5 f
四、IPC核间通信开发
下面以创龙AM57x(AM5728/AM5708)评估板源码为例,讲解IPC核间通信开发。
0 d6 h6 E) t0 x+ F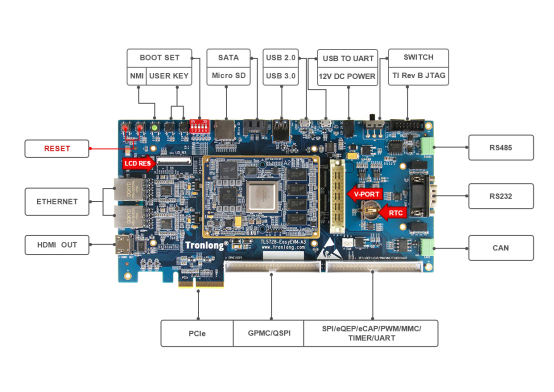 * g2 s! ]5 m* S4 j9 H. p4 r7 L0 S! a
* g2 s! ]5 m* S4 j9 H. p4 r7 L0 S! a
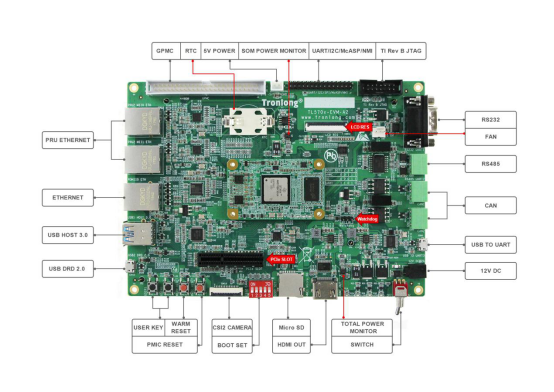 7 x$ J$ e2 s" s# J( C; c( r+ ~* l* I
7 x$ J$ e2 s" s# J( C; c( r+ ~* l* I
- 开发环境说明8 G! K& v y; b g- y
- RTOS Processor-SDK 04.03.00.05。
- Linux-4.9.65/Linux-RT-4.9.65内核。
- IPC开发包版本:3.47.01.00。
|( N' d' K* T+ P
IPC(Inter-Processor Communication)提供了一个与处理器无关的API,可用于多处理核心环境中的核间通信、与同一处理核心上的其他线程的通信(进程间)和与外围设备(设备间)的通信。IPC定义了以下几种通信组件,如下表所示,这些通信组件的接口都有以下几个共同点:
- 所有IPC通信组件的接口都由系统规范化命名。
- 在HLOS端,所有IPC接口需要使用_setup()来初始化,使用_destroy()来销毁相应的IPC Module;部分初始化还需要提供配置接口_config()。
- 所有的实例化都需要使用_create()来创建,使用_delete()来删除。
- 在更深层次使用IPC时需要用_open()来获取handle,在结束使用IPC时需要用_close()来回收handle。
- IPC的配置多数都是在SYS/BIOS下完成配置的,对于支持XDC配置的则可以使用静态配置方法。
- 每个IPC模块都支持trace信息用于调试,而且支持不同的trace等级。
- 部分IPCs提供了专门的APIs来用于提取分析信息。0 U' h* e6 T9 o! s
& ~- i: I; {" S! a; }2 b- }本小节主要演示MessageQ通信组件的运用。
# W9 K0 [: R: s b, J$ ^4 h2.MessageQ机制
- MessageQ模块特点
: l4 E# l' o& U5 C8 ~
- 支持结构化发送和接收可变长度消息。
- 一个MessageQ都将有一个读者,多个编写者。
- 既可用于同构和异构多处理器消息传递,也可用于线程之间的单处理器消息传递。
- 功能强大,简单易用。
7 K: l1 c5 Z- m1 p0 {' j$ E1 p
 0 H. b7 C4 G& t0 y3 p, G
0 H. b7 C4 G& t0 y3 p, G
2.MessageQ机制代码解释- S' f" ^$ _* ~ ?
MessageQ的传输,主要区分为发送者,跟接收者,下述为常用API的功能描述:
- MessageQ_Handle MessageQ_create (String name, MessageQ_Params *params):创建消息队列,创建队列名称将成为后面MessageQ_open的依据。
- Int MessageQ_open(String name , MessageQ_QueueId * queueId):打开创建的消息队列,获取队列ID值(ID值应为唯一值,所以创建消息队列时名称要唯一)。
- MessageQ_Msg MessageQ_alloc(UInt16 heapId, UInt32 size):申请消息空间,从heap中申请,所以需要先打开heap获取heapID,消息由MessageQ_Msg结构体长度规定。
- MessageQ_registerHeap(HeapBufMP_Handle_upCast(heapHandle),HEAPID):注册堆,分配heapID给这个堆,作为一个唯一标识符。
- Int MessageQ_put(MessageQ_QueueId queueId, MessageQ_Msg msg):发送消息到queueId对应的消息队列。
- Int MessageQ_get(MessageQ_Handle handle,MessageQ_Msg *msg,UInt timeout):从消息队列中接收消息。
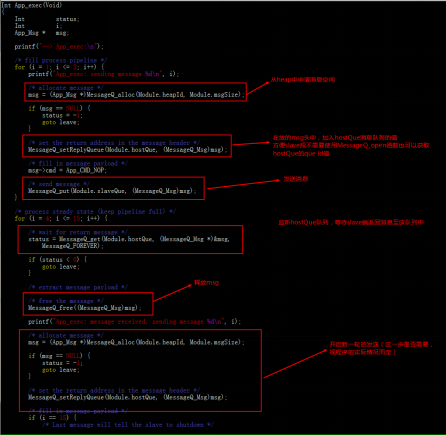
- MessageQ_free(MessageQ_Msg *msg):释放msg空间,注意不用的消息空间需要释放,不然会导致内存问题。以ex02_messageq例程为例,说明MessageQ机制的使用过程:# `& ]! f8 N9 W' G5 Q7 e& w
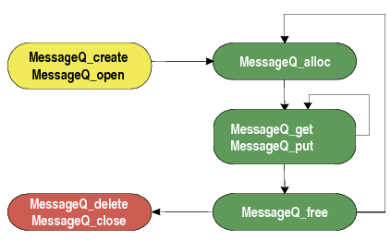
/ |, ~; @& W# w2 e9 f+ F( \' w例程运行流程图如下:
结合实际代码分析上述流程:
9 x' u: ~& k0 i, DARM:
3 V! O) H5 F; R6 i$ L2 @. Ea)创建host消息队列,打开slave消息队列。
$ d' j6 }" e( i4 M7 q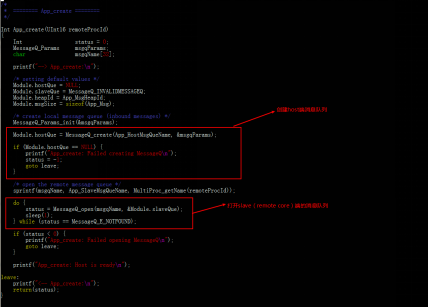 3 @6 `4 W$ x" X* Y5 @2 y1 l2 j' I
3 @6 `4 W$ x" X* Y5 @2 y1 l2 j' I
b)发送消息至slave消息队列,监听host消息队列,等待返回信息 。
c)发送shutdown消息至slave队列。 d- f5 e6 C4 ^8 n5 m' y
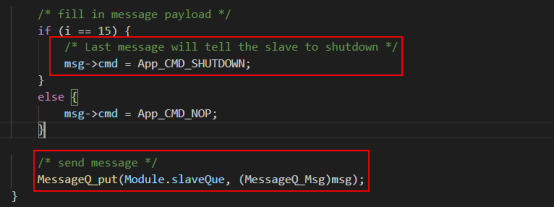 ! y8 E' B4 t6 M+ u! c9 g1 [
! y8 E' B4 t6 M+ u! c9 g1 [
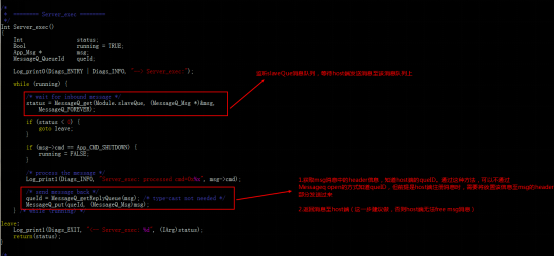
DSP:
/ C6 w$ Z9 S+ B( Ja)创建slave消息队列。1 i: E* D1 Z. ~ j
 ; c( k. N7 Z4 d2 p# c
; c( k. N7 Z4 d2 p# c
b)监听slave消息队列,并返回消息至host端。
c)接收shutdown消息,停止任务。
6 ^# Z1 S) p: ^# D8 k7 ]& o1 R 3 z) z& L* [- I# p
3 z) z& L* [- I# p
3.内存访问与地址映射问题。
首先,对于DSP/IPU子系统和L3互连之间的存储器管理单元(MMU),都用于将虚拟地址(即DSP/IPU子系统所查看的地址)转换为物理地址(即从L3互连中看到的地址)。
DSP:MMU0用于DSP内核,MMU1用于本地EDMA。
IPU:IPUx_UNICACHE_MMU用于一级映射,IPUx_MMU用于二级映射。
rsc_table_dspx.h,rsc_table_ipux.h资源表中,配置了DSP/IPU子系统的映射关系,在固件启动前,该映射关系将会写入寄存器,完成映射过程。
物理地址跟虚拟地址之间的映射关系查看:
DSP1:(默认配置mmu1的配置与mmu2的配置是一样的)
cat /sys/kernel/debug/omap_iommu/40d01000.mmu/pagetable
cat /sys/kernel/debug/omap_iommu/40d02000.mmu/pagetable
" L- ]9 S' p/ l% W0 rDSP2:(默认配置mmu1的配置与mmu2的配置是一样的)
cat /sys/kernel/debug/omap_iommu/41501000.mmu/pagetable
cat /sys/kernel/debug/omap_iommu/41502000.mmu/pagetable
! j W: O- ?8 o; q4 O' EIPU1:
cat /sys/kernel/debug/omap_iommu/58882000.mmu/pagetable
IPU2:
cat /sys/kernel/debug/omap_iommu/55082000.mmu/pagetable
Resource_physToVirt(UInt32pa,UInt32*da);
Resource_virtToPhys(UInt32da,UInt32*pa);
- 内存访问
% a3 t4 @# c; D* j$ ], H
- CMA内存6 n" D% z7 E& `4 }- P/ O
CMA内存,用于存放IPC程序的堆栈,代码以及数据段。
" a, @8 Q' u3 Sdts文件中,预留了几段空间作为从核的段空间(DDR空间):
# L$ N4 h$ |" F$ C& h% e" g% t
' V( S+ U3 j7 t9 V+ y) nIPC-demo/shared/config.bld:用于配置段空间的起始地址,以及段大小。
以DSP1为例,说明DMA中的内存映射关系:
+ A, n7 v' H) a% Z+ \& r# e) u2 Z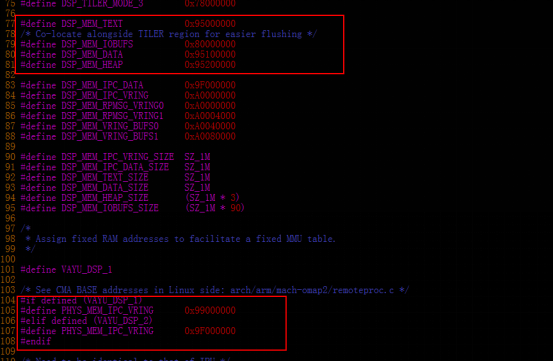
* f* o% k& p; w C8 |: C9 e p/ T通过系统中查看虚拟地址表,左边da(device address)对应的为虚拟地址,右边对应的为物理地址,那么虚拟地址的0x95000000的地址映射到的应该是0x99100002的物理地址。
cat /sys/kernel/debug/omap_iommu/40d01000.mmu/pagetable
2.共享内存
共享内存:其实是一块“大家”都可以访问的内存。
! i0 X7 t: S6 m" f+ a- c& BCMEM是一个内核驱动(ARM),是为了分配一个或多个block(连续的内存分配),更好地去管理内存的申请(一个或多个连续的内存分配block),释放以及内存碎片的回收。) k3 ?) { j; B6 z, w6 f6 ]# \
CMEM内存:由linux预留,CMEM驱动管理的一段空间。' g' f# j& }5 [6 T- ?# H$ H: ]: `
arch/arm/boot/dts/am57xx-evm-cmem.dtsi中定义了CMEM,并预留了空间出来作为共享内存(DDR & OCMC空间)。
cmem{}中最大分配的block数量为4个,cmem-buf-pools的数量没有限制。
7 f% L* M$ o: d6 J% B3 f; M5 U实际使用上,DSP与IPU访问的都是虚拟地址,所以还要完成虚拟地址到物理地址的映射关系。
. s9 U" @, J" l# B+ ]dsp1/rsc_table_dsp1.h定义了虚拟地址到物理地址的映射表,虚拟地址(0x85000000)到物理地址0xA0000000的映射,那么在DSP端访问0x85000000的地址时,实际上通过映射访问的物理地址应是0xA0000000。
cat /sys/kernel/debug/omap_iommu/40d01000.mmu/pagetable: b9 D( ]2 \, X3 f8 D. q
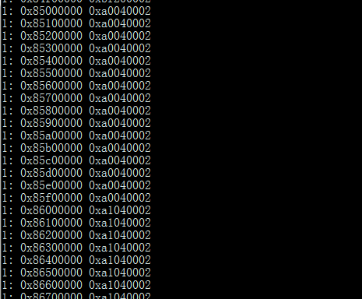
5 d5 D3 W. B) B; z0 d9 R实际应用:2 | r3 Y8 f; D5 w1 W7 S
a)初始化cmem。" v6 m0 k! }7 r, Y8 y; p9 N7 }7 F
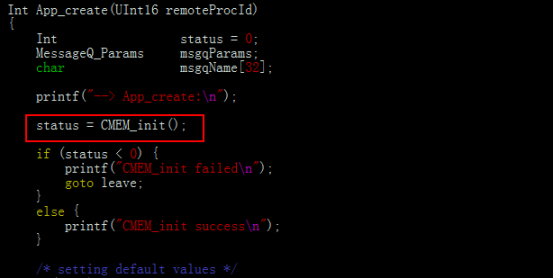 $ m5 V& x& ~5 I' c
$ m5 V& x& ~5 I' c
b)申请内存空间,并转换为物理地址(msg传输的时候传输的是物理地址,否则传输虚拟地址有不确定性)。
: k* R6 J* n4 l$ _4 n0 S, G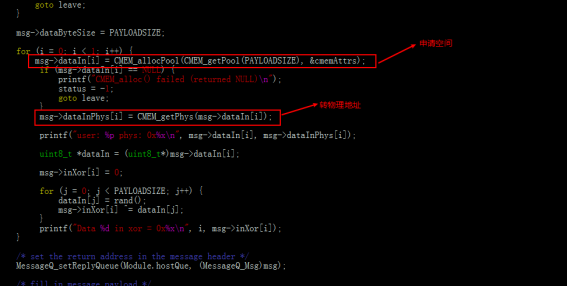 + q$ h! B h! C. b, L: w
+ q$ h! B h! C. b, L: w
DSP端的处理:接收物理地址,转换为虚拟地址进行操作,发送操作完成的结果。这里DSP需要将地址返回给ARM的话,那应该将虚拟地址转换为物理地址,再传给ARM端。1 @7 i4 I5 T, s% \% G3 \: c
 3 S; a* i6 R% c- I+ C
3 S; a* i6 R% c- I+ C
) Z# l& K) Z3 u! }. `6 d) F
0 b6 h: v# ^. G3 e
作者: CCxiaom 时间: 2020-3-26 18:27
创龙带您解密TI、Xilinx异构多核SoC处理器核间通讯
| 欢迎光临 EDA365电子论坛网 (https://bbs.eda365.com/) |
Powered by Discuz! X3.2 |